CTEM Stage 2: Discovery
Stage Summary: Discovery identifies the assets in scope and the exposures that affect them—vulnerabilities, misconfigurations, identity weaknesses, and control gaps—captured with enough evidence to support prioritization and validation.
Why Discovery Matters
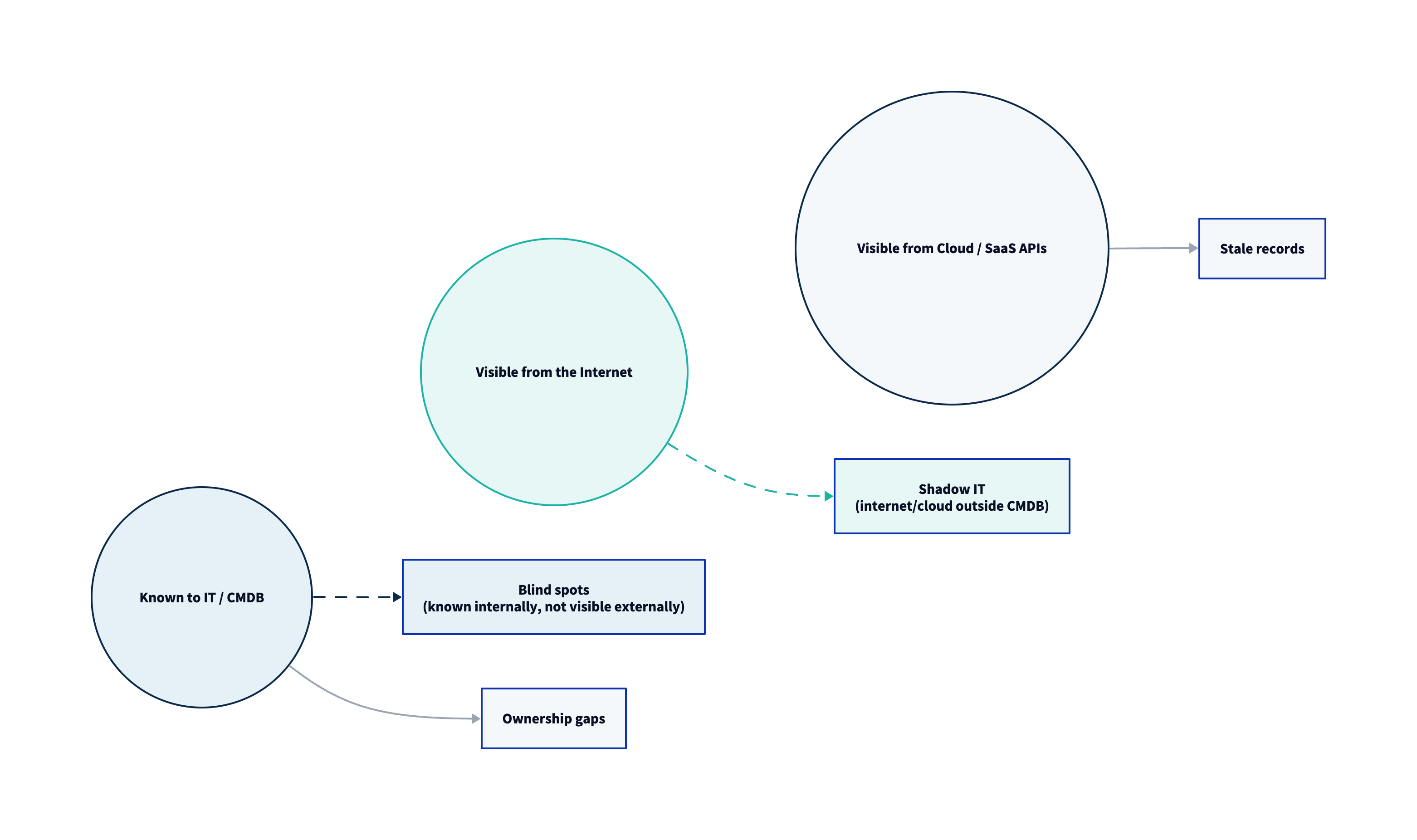
CTEM discovery is not a one-time inventory sweep. It is the discipline of maintaining continuous, high-fidelity visibility into what you own (and what you accidentally expose), with enough context to drive action.
Authoritative guidance across government and standards bodies consistently converges on this point:
- Asset visibility and vulnerability detection are foundational to measurable cybersecurity progress (e.g., CISA’s direction for asset visibility and vulnerability detection).
- Inventories must be accurate, complete for the defined boundary, and maintained at a practical level of granularity (e.g., inventory controls in common security baselines).
- Monitoring programs should continuously refine measurements and align them with risk tolerance (continuous monitoring guidance).
The CTEM nuance is what you do with discovery output: discovery is not judged by the volume of findings. It is judged by how well it enables prioritization and validation against your scoped “crown jewels.”
Discovery Outcomes
| Output | What “good” looks like | Anti-pattern |
|---|---|---|
| Asset inventory for in-scope boundary | High ownership coverage; low staleness; stable identifiers | CMDB-as-truth, stale records |
| Exposure register | Evidence-backed, deduped, actionable | One giant unverified findings list |
| Context enrichment | Reachability, identity/privilege context, business service mapping | Severity-only metadata |
| Data lineage | You can explain where each record came from and when | “Trust the tool” |
If your discovery output cannot tell you who owns an exposed condition and whether it is still present, it will not survive contact with remediation workflows.
Key Activities
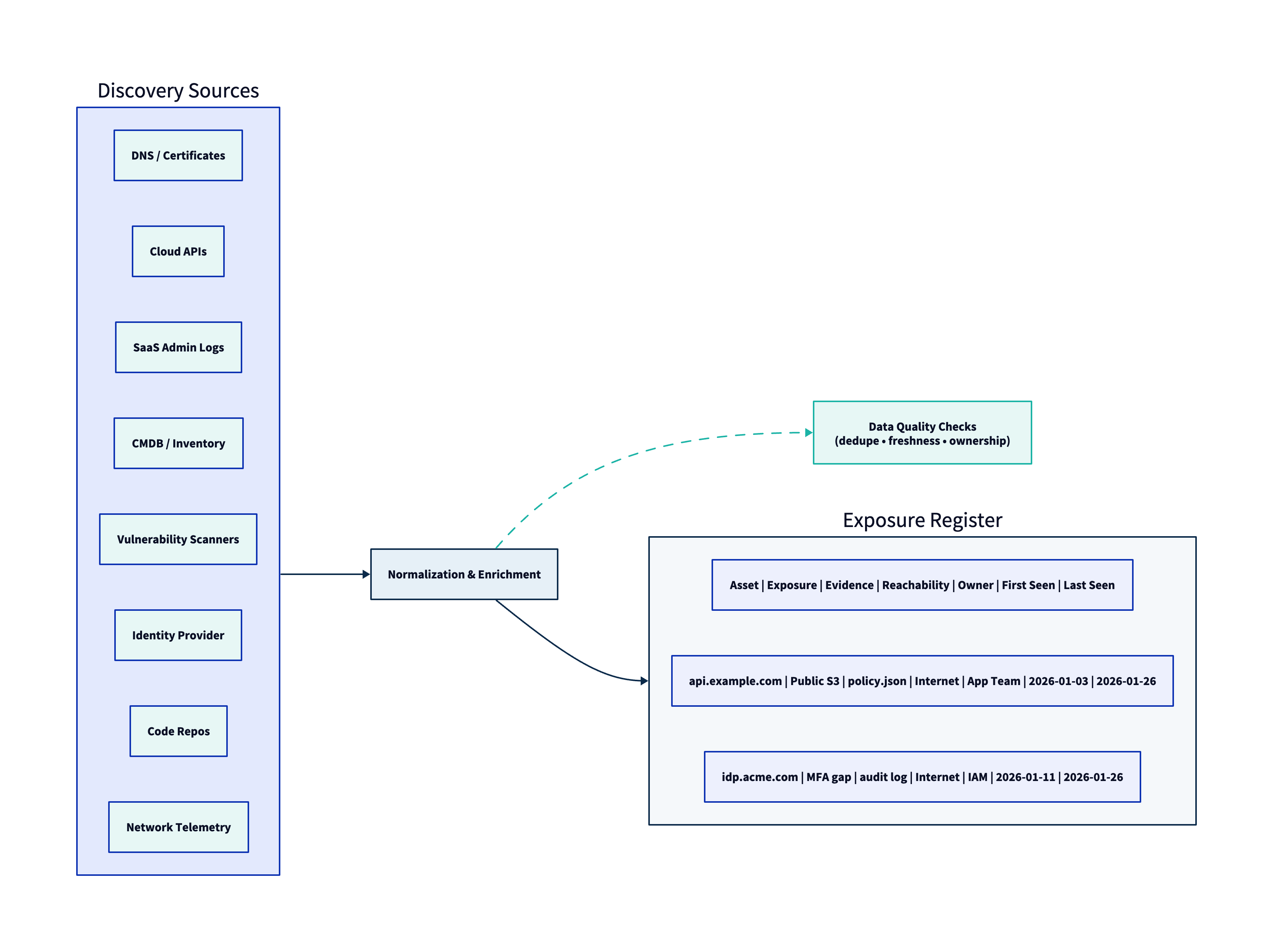
1. Establish an Authoritative Asset Inventory (for the Scope)
Discovery begins by answering “what exists?” inside the boundary you defined in Stage 1.
In mature environments, the best asset inventory is not a single system—it is a reconciled view built from multiple sources, each with known strengths:
- Cloud control planes (instances, serverless, storage, IAM roles, public endpoints)
- DNS and certificate ecosystems (domains/subdomains, cert transparency signals, newly issued certs)
- Identity providers (users, service principals, privileged roles, MFA posture)
- SaaS admin consoles (tenant configuration, sharing posture, OAuth apps, admin roles)
- Endpoint and server telemetry (agents, hostnames, OS versions)
- Network sources (DHCP, VPN, proxy logs) where appropriate
Asset inventory design constraints (worth stating explicitly)
- Stable identifiers: decide what uniquely identifies an asset class (domain, account ID, instance ID, application ID, repo ID).
- Ownership as a required field: if you can’t assign ownership, you can’t run CTEM at scale.
- Freshness SLAs: define how stale is acceptable (e.g., external domains < 24h; SaaS config < 7d; internal inventory < 7d).
2. Enumerate Exposures Beyond CVEs
CTEM discovery explicitly extends beyond classic vulnerability management. Exposures you should expect to track (depending on scope) include:
- Software vulnerabilities (CVE-based issues, dependency weaknesses)
- Configuration exposures (insecure defaults, overly permissive access, weak TLS posture)
- Identity exposures (privileged accounts without MFA, excessive permissions, stale service principals)
- SaaS posture gaps (public sharing, risky OAuth apps, unmanaged admin roles)
- Attack-path primitives (reachable management interfaces, exposed secrets, weak segmentation)
- Third-party integration exposures (overprivileged integrations, insecure vendor connectivity patterns)
A useful working definition in CTEM programs:
- Vulnerability: a flaw in software/hardware.
- Exposure: a condition that increases the likelihood or impact of compromise (can include vulnerabilities, but also misconfigurations, identities, and control gaps).
This framing matters because the most exploitable conditions are often combinations: a reachable service + weak auth + overprivileged identity + exposed data.
3. Capture Evidence and Context (Not Just Findings)
Discovery output must be defensible. For each exposure record, capture:
- Evidence: what you saw (config snippet, response header, policy state, scanner evidence ID)
- Timestamping: first seen / last seen (and a confidence interval if applicable)
- Reachability: internet-facing, partner-facing, internal-only, or segmented
- Privilege context: does exploitation require auth? which role? is MFA enforced?
- Business mapping: which critical service/asset category does this affect?
- Compensating controls (if known): WAF, segmentation, EDR, conditional access, etc.
Without evidence, remediation teams will push back (correctly), and validation teams will waste time re-discovering the same condition.
4. Normalize, Deduplicate, and Validate Data Quality
High-volume discovery without normalization becomes unusable. Minimum hygiene:
- Deduplicate exposures across tools (same CVE, same asset, multiple sources)
- Normalize naming (domains, hostnames, cloud resource tags, repo names)
- Enforce schemas (asset classes and exposure types are enumerable; avoid free-text chaos)
- Ownership resolution (use tags, repo ownership files, directory groups, service catalogs)
- Freshness checks (stale assets/exposures are explicitly marked and re-verified)
Discovery Templates
Template A: Exposure Register (minimum viable)
| Field | Description |
|---|---|
| Exposure ID | Unique ID for the exposure record |
| Asset ID / Name | Domain, resource ID, app/service identifier |
| Asset class | App/API, SaaS tenant, identity object, cloud resource, endpoint |
| Business service | Which scoped service this supports |
| Exposure type | CVE, misconfiguration, identity weakness, control gap |
| Severity signal | CVSS (if applicable) or internal severity |
| Evidence | Link/ID to supporting evidence (redacted if needed) |
| Reachability | Internet / partner / internal |
| Preconditions | Auth required? privilege required? |
| Owner | Team/individual accountable |
| First seen / last seen | Timestamps |
| Status | Open / mitigated / accepted / false positive |
| Notes | Compensating controls, change windows, etc. |
Template B: Data Quality Scorecard (for discovery health)
| Metric | Target | Why it matters |
|---|---|---|
| % assets with assigned owner | ≥ 95% | Enables mobilization |
| % exposures with evidence | ≥ 90% | Enables validation and remediation trust |
| Median “last seen” age (external) | < 48h | Keeps external reality current |
| Deduplication rate | Increasing early, stabilizing later | Indicates normalization maturity |
| “Unknown asset” rate | Trending down over time | Indicates reduced shadow IT |
Common Pitfalls
- Counting findings as success. Volume is not fidelity.
- Relying on a single source of truth. Every inventory source lies somewhere; reconcile.
- Ignoring identity and SaaS discovery. Modern environments are identity-anchored and SaaS-heavy.
- No evidence, no timestamps. “We think it’s exposed” doesn’t survive triage.
- No ownership mapping. Unassigned exposures accumulate indefinitely.
- Stale discovery cadences. Quarterly discovery in a cloud-first enterprise is effectively historical reporting.
Next Steps
With an evidence-backed exposure register in hand, move to Prioritization to decide what matters most.
References (non-vendor)
- Gartner CTEM Step 2 framing (discovery vs scoping): https://www.gartner.com/en/articles/how-to-manage-cybersecurity-threats-not-episodes
- CISA directive on asset visibility and vulnerability detection: https://www.cisa.gov/news-events/directives/bod-23-01-improving-asset-visibility-and-vulnerability-detection-federal-networks
- NIST continuous monitoring guidance (metrics + ongoing monitoring): https://nvlpubs.nist.gov/nistpubs/legacy/sp/nistspecialpublication800-137.pdf
- NIST SP 800-53 (inventory control baseline concepts): https://csrc.nist.gov/pubs/sp/800/53/r5/upd1/final