CTEM vs Vulnerability Management
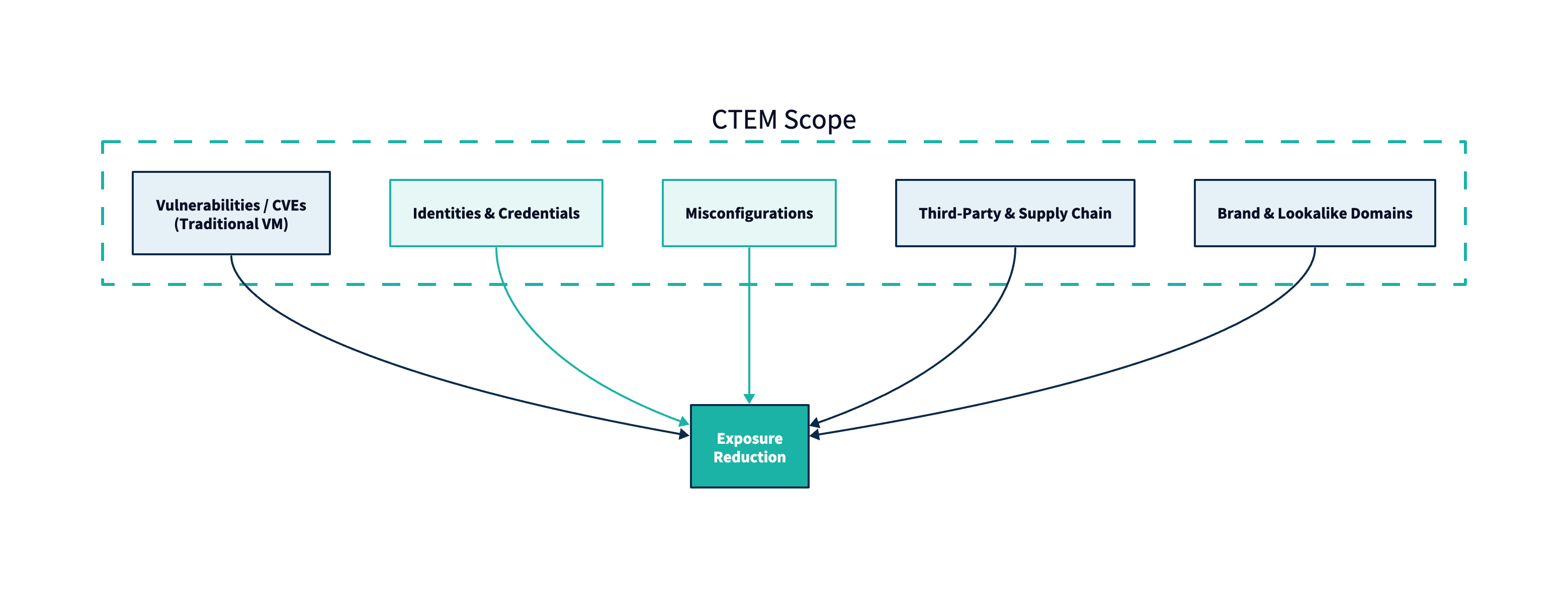
Vulnerability Management (VM) is primarily about discovering and remediating known software flaws (e.g., CVEs) across inventoried assets. Continuous Threat Exposure Management (CTEM) is broader and more outcome-driven: it continuously reduces material exposure across the full attack surface—including identities, misconfigurations, third parties, and “unpatchable” conditions—based on business impact and how an adversary would actually get in.
- VM answers: “What CVEs do we have, and are we meeting patch SLAs?”
- CTEM answers: “What exposures meaningfully increase the probability of a business-impacting incident, and what should we change first?”
- VM is necessary, but not sufficient. Modern breaches routinely combine vulnerabilities with identity weakness, misconfiguration, and third-party pathways. CTEM is the program structure that keeps those dimensions continuously prioritized, validated, and owned.
Overview
Why this comparison matters now
Most security teams have improved at finding vulnerabilities. The limiting factor is usually decision quality and mobilization:
- Which findings are actually reachable by real attackers?
- Which ones sit on a path to “crown jewel” systems or sensitive data?
- Which exposures can’t be “patched” at all (identity, misconfiguration, SaaS posture, vendor access)?
- Which fixes require cross-team ownership and sequencing?
A useful way to frame the gap is risk: NIST defines risk as a function of both likelihood and impact. Traditional VM often optimizes around technical severity. CTEM operationalizes likelihood plus impact by continuously aligning exposure reduction with business outcomes.
Definitions (practitioner-friendly)
-
Vulnerability Management (VM): A repeatable process to identify, assess, prioritize, remediate, and verify remediation of vulnerabilities—most commonly software vulnerabilities cataloged as CVEs—across enterprise assets.
If you’re mapping to common baselines, VM is explicitly called out in CIS Control 7 (Continuous Vulnerability Management), and patching is covered in depth by NIST SP 800-40 Rev. 4. -
Continuous Threat Exposure Management (CTEM): A program (not a single tool) that continuously reduces exposure by iterating through a structured cycle—commonly described as Scope, Discover, Prioritize, Validate, Mobilize—with emphasis on attack paths, exploitability, and business context. Gartner formalized this cycle and emphasizes that scoping must extend beyond typical VM programs (external attack surface, SaaS posture, code repos, supply chain integrations, etc.).
Scope Comparison
| Aspect | Vulnerability Management | CTEM |
|---|---|---|
| Primary question | “What vulnerabilities exist?” | “What exposures materially increase business risk?” |
| Focus | Software flaws (typically CVEs) | Any exposure: vulnerabilities, misconfigs, identities, data paths, third parties, brand attack surface |
| Asset coverage | Known, inventoried IT assets | Full attack surface (including unknown/external/SaaS and identity planes) |
| Cadence | Often scan-based, periodic-to-continuous | Continuous, iterative program cycle tied to threat and business change |
| Prioritization | Often CVSS-heavy; sometimes SLA-based | Business criticality + exploit evidence/probability + reachability + attack paths + compensating controls |
| Validation | Frequently limited to “rescan confirms patch” | Explicit validation of exploitability & pathways (control testing, attack simulation, purple teaming where appropriate) |
| Output | Vulnerability backlog; patch metrics | A prioritized exposure-reduction backlog tied to outcomes, owners, and deadlines |
| Governance | Often security-led | Cross-functional: security + infrastructure + app teams + IAM + cloud + procurement/vendor mgmt |
Many mature VM programs already do “risk-based” prioritization (asset criticality, KEV/EPSS, exploit intel). That’s good—but it still tends to be CVE-centered. CTEM is the umbrella operating model that keeps vulnerabilities and non-CVE exposures continuously scoped, validated, and mobilized.
Vulnerability Management in practice
What VM reliably does well
A strong VM program delivers consistent, auditable execution of the fundamentals:
- Continuous discovery of vulnerabilities (authenticated scanning where feasible).
- Patch and remediation workflows (including compensating controls when patching isn’t feasible).
- Verification (rescan, config drift checks, and evidence for auditors).
- Metrics for operational health (time-to-remediate, SLA compliance, exception handling, aging).
This aligns closely with the intent of CIS Control 7 and NIST’s guidance on patch management planning and governance (NIST SP 800-40 Rev. 4).
Where VM commonly breaks down
VM is often judged by backlog size and SLA adherence, but the failure modes are subtler:
-
Severity is not risk.
CVSS was designed to communicate technical severity, not your organization’s risk in context. A CVSS 9.8 in an unreachable service with strong compensating controls may be lower risk than a CVSS 6.5 on an internet-facing identity-adjacent service with active exploitation. -
Reachability and attack paths are under-modeled
“Is this exploitable?” is different from “Can an attacker reach it in our environment and turn it into a meaningful outcome?” -
Signal scarcity and overload coexist
Teams frequently drown in findings but lack confidence about what will become tomorrow’s incident. Operational reality: you will never fix everything. -
Non-CVE exposures are out of band
Credential leaks, risky OAuth app grants, orphaned DNS records, overly permissive cloud policies, exposed admin portals, and vendor access paths often sit in other tools and other backlogs.
If your VM prioritization algorithm is “sort by CVSS and open tickets,” you will create a predictable outcome: high work output with inconsistent risk reduction. Use CVSS as an input, not the decision.
Better prioritization signals (still within VM)
If you’re staying within the VM domain, two practical enrichment sources dramatically improve prioritization:
- CISA Known Exploited Vulnerabilities (KEV): a curated catalog of vulnerabilities with evidence of exploitation in the wild—useful as a “do these first” input.
- FIRST EPSS: a probability model estimating likelihood of exploitation activity over a near-term horizon—useful for separating “theoretically bad” from “operationally urgent.”
You can also incorporate a decision-tree methodology such as SSVC (Stakeholder-Specific Vulnerability Categorization) to drive consistent response decisions tied to stakeholder impact.
CTEM: what it adds (and why it’s not just “better VM”)
CTEM takes the parts that work in VM—discovery, prioritization, remediation discipline—and extends them into a continuous exposure-reduction program that:
- Scopes the problem intentionally (not “scan everything and hope the list helps”).
- Discovers exposure across multiple planes (external, SaaS, identities, code, supply chain).
- Prioritizes based on material risk, not only severity.
- Validates what’s actually exploitable and consequential.
- Mobilizes owners and removes friction to drive change.
Gartner’s public CTEM guidance is explicit that scoping should extend beyond typical VM programs, including external attack surface and SaaS posture as pragmatic starting points.
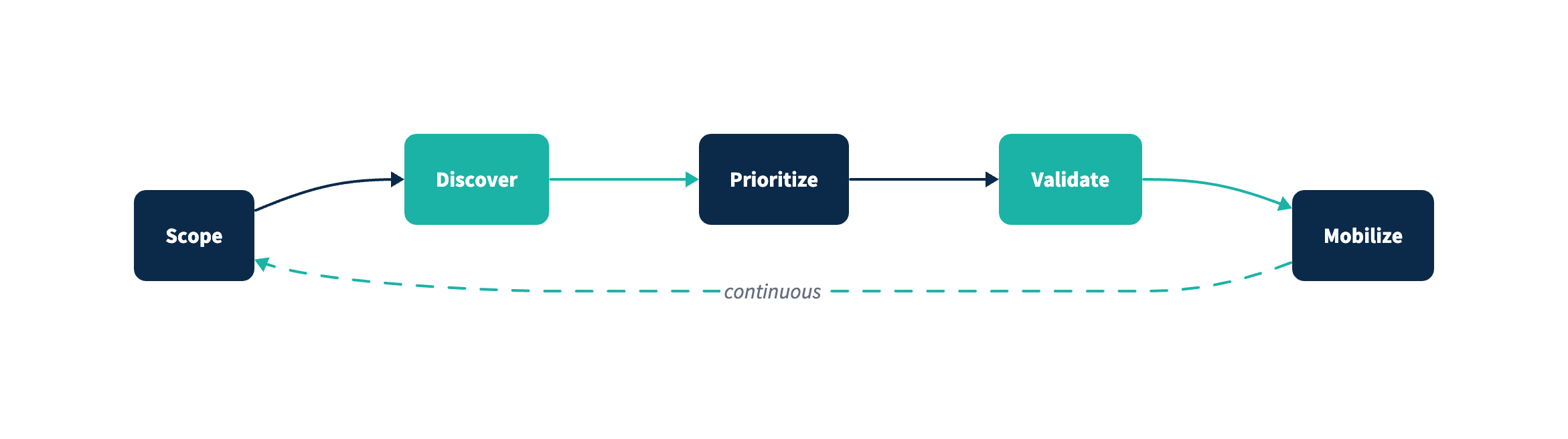
The CTEM stages (with “what good looks like” outputs)
| Stage | What you do | What “good” produces |
|---|---|---|
| Scope | Define a bounded problem tied to business risk (e.g., “internet-facing identity pathways to finance apps”) | A clear scope statement, success criteria, and owners |
| Discover | Enumerate relevant assets, identities, pathways, and exposures in that scope | A normalized exposure inventory (not just scanner output) |
| Prioritize | Rank by business impact + exploitability + reachability + compensating controls | A short list of exposures that matter this cycle |
| Validate | Prove exploitability/path-to-impact; test control assumptions | High-confidence findings, reduced false positives, clearer fixes |
| Mobilize | Assign owners, sequence changes, clear approvals, measure outcomes | A delivered reduction in exposure, not just tickets created |
CTEM is an operating model. It typically reuses existing tools (scanners, CSPM, IAM telemetry, BAS/purple teaming inputs, asset inventories) but changes the way findings are scoped, prioritized, validated, and owned.
What CTEM covers that classic VM doesn’t
Below are exposure categories that routinely drive incidents but often fall outside traditional CVE-based workflows.
Credential leaks and secret exposure
Compromised credentials and leaked secrets (API keys, tokens, SSH keys, service account credentials) that can be used directly for access—often without exploiting a CVE.
Why it matters: Modern intrusions frequently start with identity. Once an attacker has valid credentials or tokens, they can bypass many perimeter-oriented controls. Industry reporting also shows that leaked secrets can linger for long periods before being remediated—an exposure window that is hard to justify when measured against business risk.
CTEM approach (practical):
- Scope: Identify the “credential blast radius” for crown-jewel systems and key SaaS tenants.
- Discover: Collect signals from code repositories, CI/CD, secrets scanning, and identity platforms.
- Prioritize: Elevate credentials with privileged access, broad scopes, or access to sensitive data paths.
- Validate: Confirm whether the credential still works, what it can access, and what compensating controls exist.
- Mobilize: Rotate/revoke rapidly, fix root causes (secret management, least privilege, token lifetimes), and instrument detection.
Useful metrics:
- Median time to rotate/revoke exposed secrets
- Number of privileged credentials with no enforced MFA
- “Credential exposure pathways” to crown jewels reduced quarter-over-quarter
Lookalike domains and brand attack surface
Domains and subdomains that impersonate your brand (typosquatting, homoglyph domains, “evil twin” domains), used for phishing, credential theft, and business email compromise.
Why it matters: This exposure sits outside classic VM. You can have immaculate patch hygiene and still lose credentials through a convincing lookalike domain and a well-timed lure.
CTEM approach:
- Scope: Define which brands, domains, and business processes are in scope (e.g., payroll, vendor payments, executive comms).
- Discover: Monitor newly registered lookalike domains, certificate issuance, DNS changes, and phishing telemetry.
- Prioritize: Focus on domains actively hosting content, sending mail, or targeting high-risk workflows.
- Validate: Confirm hosting content, credential collection, or mail-sending capability.
- Mobilize: Takedown, legal/registrar workflows, user comms, and hardening (DMARC enforcement, recipient protections, high-risk workflow controls).
Useful metrics:
- Time from lookalike domain detection to takedown
- DMARC policy maturity and enforcement status
- High-risk workflow fraud attempts blocked
Misconfigurations
Insecure or unintended configuration states: overly permissive cloud storage policies, exposed admin interfaces, insecure IAM conditions (e.g., dormant privileged accounts), SaaS tenant misconfigurations, or network/service exposure caused by change drift.
Why it matters: Misconfigurations are often unpatchable—there is no vendor fix. They require control ownership, change management, and continuous drift detection. They also frequently act as accelerants: a low/medium CVE becomes high-impact when paired with permissive identity and reachable pathways.
CTEM approach:
- Scope: Start with the configurations that gate access to sensitive data and critical services.
- Discover: Treat config as “exposure inventory,” not as a compliance checklist.
- Prioritize: Tie misconfigs to reachable attack paths and high-impact assets.
- Validate: Confirm what an attacker could do right now (data access, privilege escalation, lateral movement).
- Mobilize: Fix in infrastructure-as-code, enforce policy-as-code, and add regression testing to prevent reintroduction.
Useful metrics:
- Misconfiguration recurrence rate (fixed → reintroduced)
- Number of critical services reachable from the internet without strong auth
- Exposure drift MTTR (mean time to remediate drift)
Third-party risk and supply-chain exposure
Exposure created through vendors, MSPs, SaaS integrations, federated identity, shared credentials, API tokens, and network connectivity that expands your attack surface beyond what you directly control.
Why it matters: A third party can become your initial access vector. When third-party relationships are treated as static due diligence artifacts rather than continuously monitored access pathways, risk accumulates silently.
CTEM approach:
- Scope: Identify “tier 0” third parties (access to identity, sensitive data, payments, production control planes).
- Discover: Inventory integrations (SSO, OAuth grants, API tokens, network tunnels), not just contracts.
- Prioritize: Focus on high-privilege access, weak authentication, shared accounts, and high-impact workflows.
- Validate: Confirm what access exists and whether it’s monitored and revocable.
- Mobilize: Tighten access, implement least privilege, create rapid offboarding procedures, and run tabletop exercises that include third-party failure modes.
Useful metrics:
- Time to revoke third-party access (planned and emergency)
- Count of high-privilege vendor accounts without modern auth controls
- Visibility coverage of third-party access paths into crown jewels
Using both together
VM is a critical input to CTEM. The highest-performing programs do not choose between them—they use VM as a high-volume hygiene engine and CTEM as a risk-reduction governor.
A reference operating model
-
Keep VM strong and measurable
- Authenticated scanning where feasible
- Patch governance (including exceptions and compensating controls)
- Verification and evidence for audits
-
Feed VM findings into a CTEM cycle
- Normalize vulnerability data with asset criticality, reachability, and exploit signals (KEV/EPSS).
- Add non-CVE exposures (identity, misconfig, third-party, brand).
- Generate a single exposure backlog tied to business outcomes.
-
Validate and sequence
- Validate exploitability and attack paths for the top exposures.
- Sequence fixes to reduce the highest-risk paths first (not the loudest tool output).
-
Mobilize owners
- Assign accountable owners and remove friction (approvals, change windows, runbooks).
- Measure exposure reduction, not just ticket throughput.
A lightweight “starter” CTEM pilot (90 days)
Days 0–30: Scope
- Pick one bounded domain where outcomes are clear:
- External attack surface → critical apps
- SaaS posture for a business-critical tenant
- Identity pathways to privileged roles
Days 31–60: Discover & Prioritize
- Build a unified inventory (assets + identities + integrations).
- Apply risk signals (business criticality, KEV/EPSS, reachability, compensating controls).
Days 61–90: Validate & Mobilize
- Validate the top 10–25 exposures end-to-end (what’s the path? what’s the fix? who owns it?).
- Deliver a measurable reduction in one or two high-risk pathways.
- Publish outcome-driven metrics that executives can understand.
Instead of “we closed 1,200 vulns,” report:
- “We eliminated X externally reachable paths to sensitive data,”
- “We reduced exposure in high-risk workflows (payments, identity admin) by Y%,”
- “Median time-to-remediate known exploited issues is now Z days.”
Metrics: what to measure (so it doesn’t devolve into theater)
| Metric category | VM-aligned metrics | CTEM-aligned metrics |
|---|---|---|
| Speed | MTTR by severity class; SLA compliance | MTTR for validated high-risk exposures; time-to-break attack paths |
| Quality | False positive rate; rescan confirmation | Validation yield; recurrence rate; control regression rate |
| Risk reduction | Vulnerability count reduction | Reduction in reachable, exploitable exposure to crown jewels |
| Governance | Exception aging; patch policy adherence | Owner acceptance rates; cycle completion rate; blocked-by workflow issues |
| Exposure coverage | % assets scanned | % critical assets + identities + integrations covered in CTEM scope |
FAQ
Does CTEM replace vulnerability management?
No. CTEM depends on VM as one of its core data sources. CTEM is best understood as the program layer that ensures VM work translates into measurable exposure reduction.
Is “risk-based vulnerability management” the same as CTEM?
Not quite. RBVM improves how you prioritize CVEs. CTEM expands the problem definition to include non-CVE exposures and requires validation and mobilization as first-class steps.
What’s the minimum viable CTEM scope?
Pick something bounded and high-signal: external attack surface to critical apps, SaaS posture for a key tenant, or identity pathways for privileged access. Avoid “boil the ocean” scoping.
How do KEV and EPSS fit into this?
They are prioritization enrichments: KEV captures known exploited vulnerabilities; EPSS estimates likelihood of exploitation. Both are useful in VM and CTEM—but CTEM adds business impact, reachability, and validation.
What does “validate” mean in CTEM?
Validation is evidence that an exposure is exploitable and consequential in your environment. That can include attack-path analysis, controlled exploit validation, and testing that compensating controls behave as assumed.
What’s the biggest failure mode when teams attempt CTEM?
Treating CTEM as a tooling refresh instead of a cross-functional program with scoped outcomes, validation, and mobilization. The result is “more dashboards, same bottlenecks.”
References and primary sources
-
Gartner on CTEM and the five-step process (Scope → Discover → Prioritize → Validate → Mobilize):
-
Vulnerability management and patch governance:
-
Risk, severity, and exploit probability:
-
Exploitation and incident trends (for grounding exposure decisions):
-
Prioritization methodology beyond scores (decision trees):
-
Phishing/brand exposure context: